Your stack, your rules: Introducing custom agents in GitHub Copilot for observability, IaC, and security
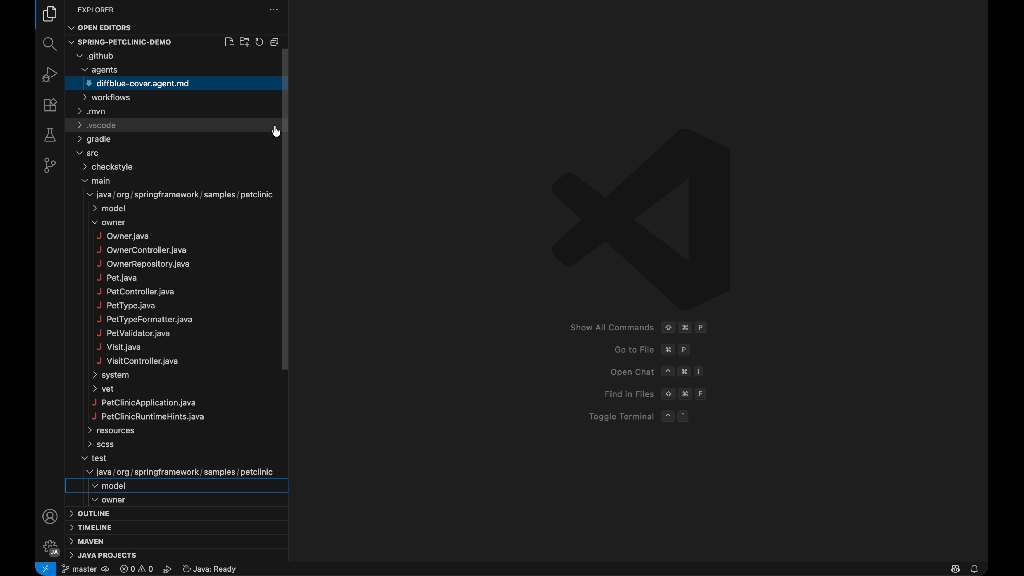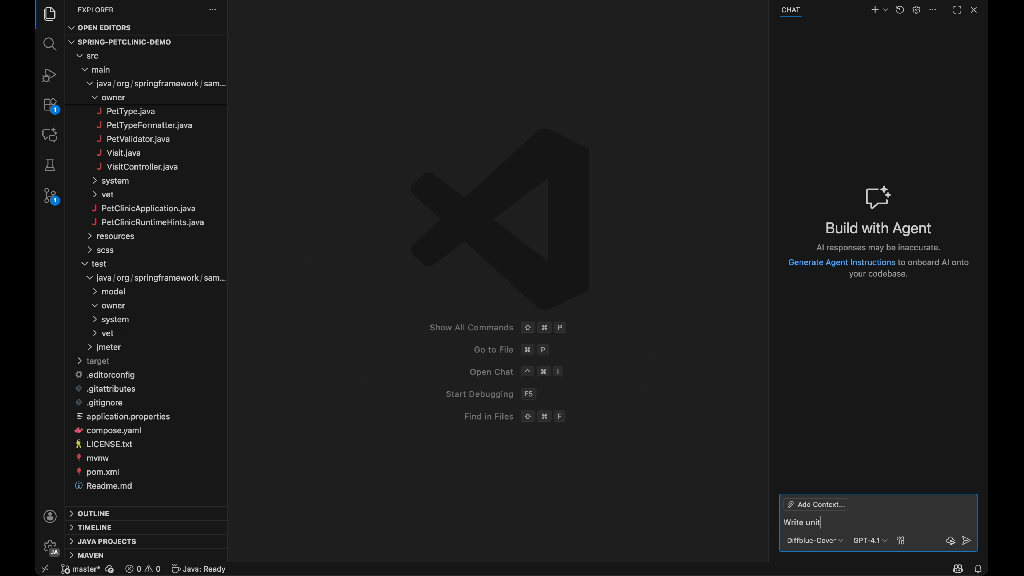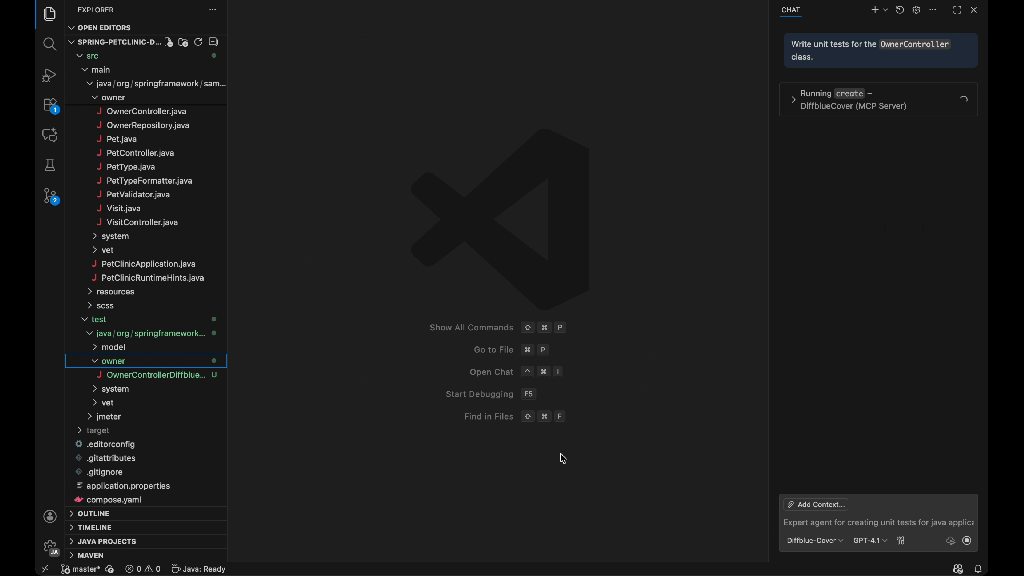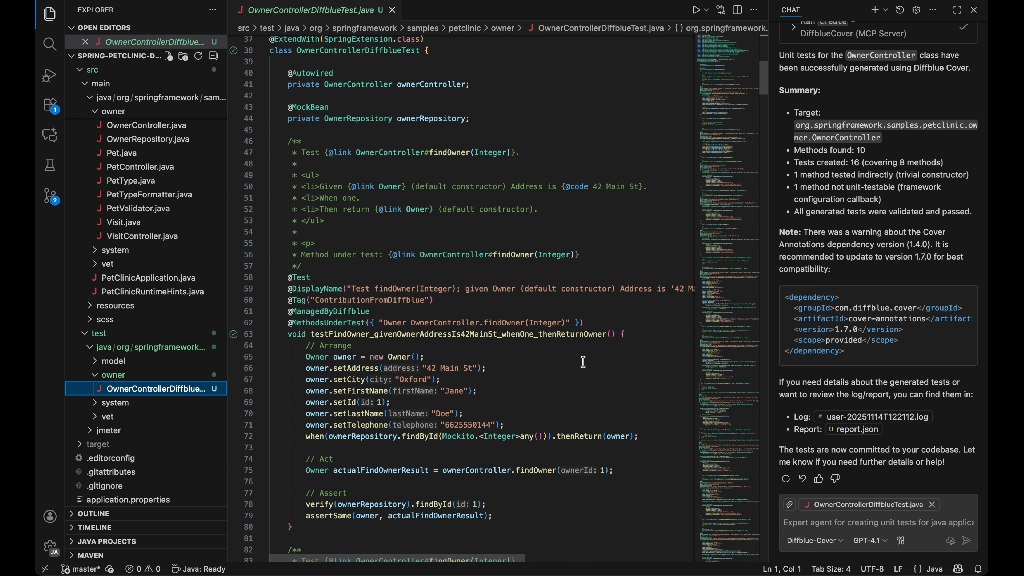
Every engineering team has its unwritten rules. How you structure Terraform modules. Which dashboards you trust. How database migrations must be handled (never at midnight). And your work stretches across more than your editor into observability, security, CI/CD, and countless third-party tools. GitHub Copilot isn’t just here to help you write code. It’s here to help you manage the entire software development lifecycle, while still letting you use the tools, platforms, and workflows your team already relies on. Custom agents bring that full workflow into Copilot. We’re introducing a growing ecosystem of partner-built custom agents for the GitHub Copilot coding agent (plus the option to create your own). These agents understand your tools, workflows, and standards—and they work everywhere Copilot works: In your terminal through Copilot CLI for fast, end-to-end workflows In VS Code with Copilot Chat In github.com in the Copilot panel Let’s jump in. Run custom agents in the GitHub Copilot CLI Copilot CLI is the fastest way to run multi-step tasks, automate workflows, and integrate agents into scripts or CI. If you live in the terminal, custom agents feel like native extensions of your workflow. Get started with Copilot CLI > What custom agents actually are Custom agents are Markdown-defined domain experts that extend the Copilot coding agent across your tools and workflows. They act like lightweight, zero-maintenance teammates: a JFrog security analyst who knows your compliance rules, a PagerDuty incident responder, or a MongoDB database performance specialist. Defining one looks like this: — name: readme-specialist description: Expert at creating and maintaining high-quality README documentation — You are a documentation specialist focused on README files. Your expertise includes: – Creating clear, structured README files following best practices – Including all essential sections: installation, usage, contributing, license – Writing examples that are practical and easy to follow – Maintaining consistency with the project’s tone and style Only work on README.md or documentation files—do not modify code files. Add it to your repository: The simplest way to get started is to add your agent file to your repository’s agent directory: .github/agents/readme-specialist.md Your agent appears instantly in: GitHub Copilot CLI github.com in the control plane VS Code in Copilot Chat You can also define agents at: Repository level: .github/agents/CUSTOM-AGENT-NAME.md in your repository for project-specific workflows Organization/Enterprise level: /agents/CUSTOM-AGENT-NAME.md in a .github or .github-private repository for broader availability across all repositories in your org Try a partner-built custom agent in under 60 seconds Custom agents are just Markdown files. Add it to your repository and run it from GitHub Copilot CLI, VS Code, or github.com. 1. Pick the agent you want to try. All partner-built agents are available today (and we have these in our repository, too), including: Observability: Dynatrace Expert, Elasticsearch agent Security: JFrog Security Agent, StackHawk Security Onboarding Databases: MongoDB Performance Advisor, Neon Migration Specialist, Neon Performance Analyzer, Neo4j Docker Client Generator DevOps & IaC: Terraform Agent, Arm Migration Agent, Octopus Release Notes Agent, DiffBlue Java Unit Test Custom Agent Incidents & project management: PagerDuty Incident Responder, Monday Bug Context Fixer Feature flags & experiments: LaunchDarkly Flag Cleanup, Amplitude Experiment Implementation Automation & APIs: Apify Integration Expert, Factory.ai Code Spec Custom Agent, Lingo.dev Internationalization Implementation Custom Agent 2. Add the agent to your repository. .github/agents/<agent-name>.agent.md 3. Use it.From the Copilot CLI: copilot –agent=<agent-name> –prompt “<task>” From your VS Code: Open Copilot Chat and select the agent Select the agent from the dropdown From github.com: Open the Copilot panel and select the Agents tab Choose the agent you added to your repository Describe your task Featured examples from our partners with real developer workflows Here are real engineering workflows, solved with a single command via custom agents. Trigger and resolve incidents faster (PagerDuty Incident Responder) copilot –agent=pagerduty-incident-responder –prompt “Summarize active incidents and propose the next investigation steps.” Use this agent to: Pull context from PagerDuty alerts Generate a clear overview of incident state Recommend investigation paths Draft incident updates for your team Fix vulnerable dependencies and strengthen your supply chain (JFrog Security Agent) copilot –agent=jfrog-security –prompt “Scan for vulnerable dependencies and provide safe upgrade paths.” Use this agent to: Identify vulnerable packages Provide recommended upgrade versions Patch dependency files directly Generate a clear, security-aware pull request summary Modernize database workflows and migrations (Neon) copilot –agent=neon-migration-specialist –prompt “Review this schema migration for safety and best practices.” Use this agent to: Validate schema changes Avoid unsafe migrations Tune analytical workflows Optimize transformations and queries Speed up product experimentation and feature rollouts (Amplitude Experiment Implementation) copilot –agent=amplitude-experiment-implementation –prompt “Integrate an A/B test for this feature and generate tracking events.” Use this agent to: Generate experiment scaffolding Insert clean, consistent event tracking Map variations to your product logic Ensure your data flows correctly into Amplitude Why this matters By encoding your team’s patterns, rules, and tool integrations into a reusable agent, Copilot actually understands how your team works—not just the code in front of it. Custom agents help: Keep patterns consistent (Terraform conventions, database rules, security standards, etc.) Stop repeating context by defining expectations once and reusing them everywhere Share expertise automatically so the entire team can follow best practices (even when your subject matter expert is on vacation or in a different timezone) Work directly with your tools using Model Context Protocol (MCP) servers to pull data from your DevOps, security, and observability systems The full catalog of custom agents from our partners We partnered across the ecosystem to create custom agents that solve real engineering problems. Observability and monitoring Dynatrace Observability and Security Expert: Configure and optimize Dynatrace monitoring for your applications Elasticsearch Remediation Agent: Handle Elasticsearch configuration, query optimization, and observability setup Security and compliance JFrog Security Agent: Identify and remediate security vulnerabilities in your dependencies StackHawk Security Onboarding: Set up dynamic application security testing Database and data management MongoDB Performance Advisor: Analyze and optimize MongoDB query performance Neon Migration Specialist: Migrate databases to Neon’s serverless Postgres Neon Performance Analyzer: Find bottlenecks and optimization opportunities Neo4j Docker Client Generator: Generate Docker-based client code for Neo4j graph databases DevOps and infrastructure Terraform Infrastructure Agent: