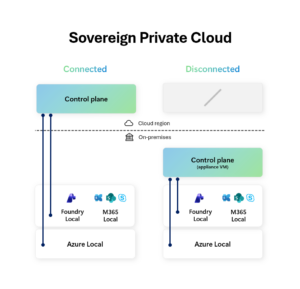
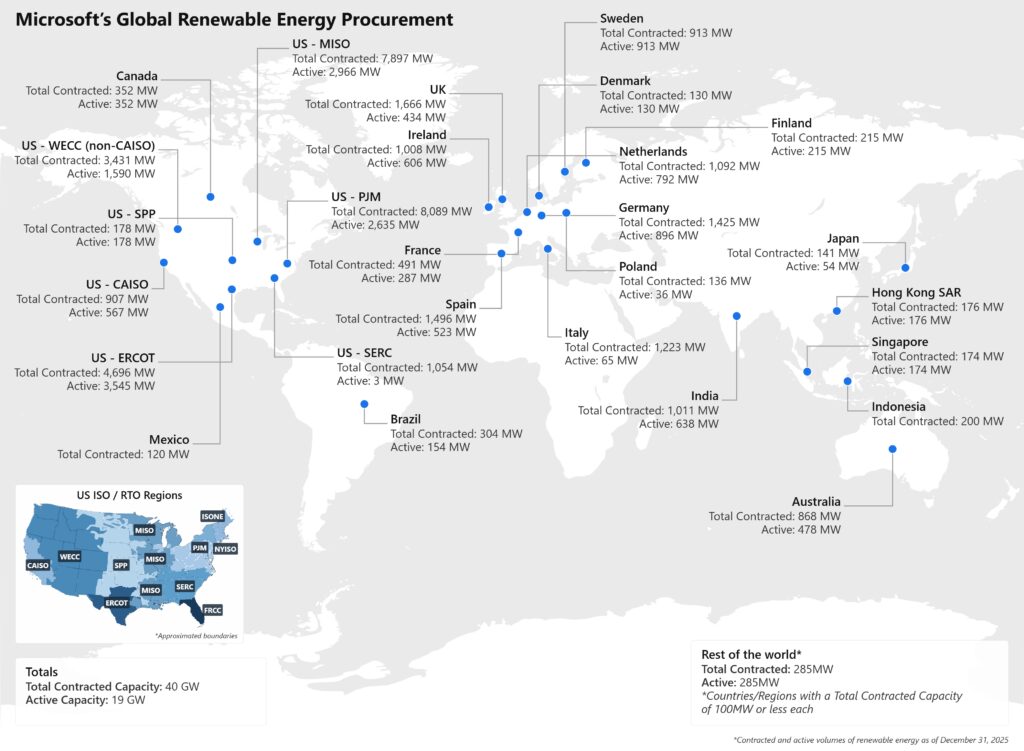
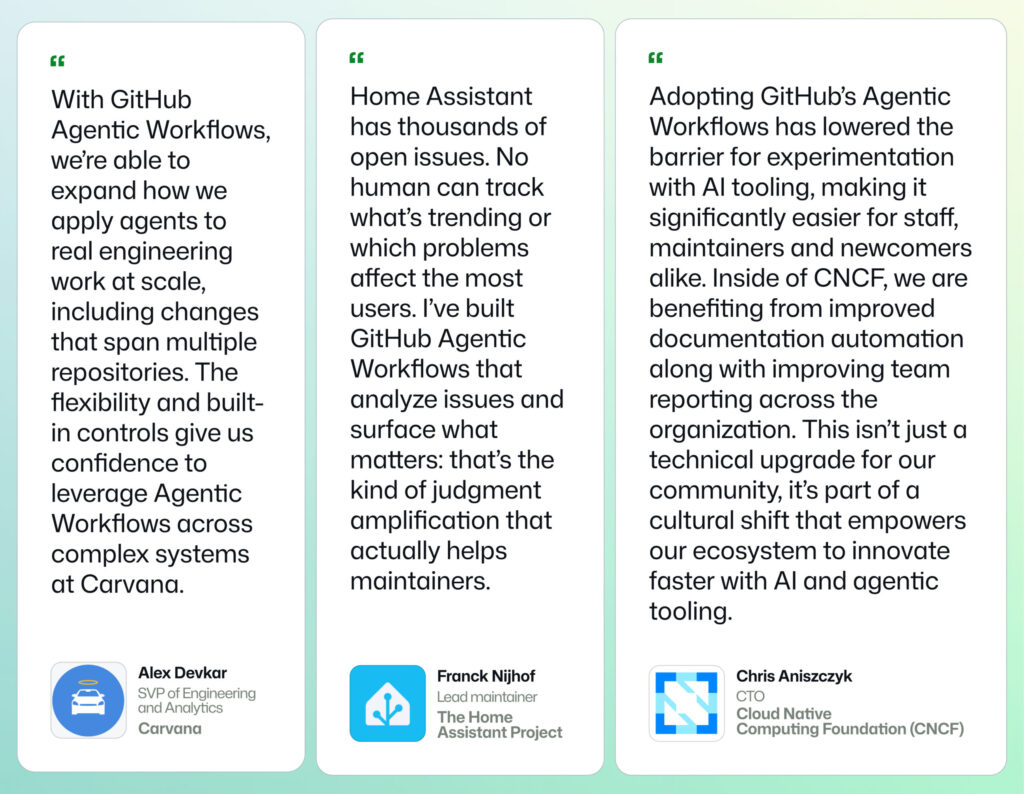
As digital sovereignty becomes a strategic requirement, organizations are rethinking how they deploy critical infrastructure and AI capabilities under tighter regulatory expectations and higher risk conditions. Microsoft’s approach to sovereignty is grounded in enabling enterprises, public sectors and regulated industries to participate in the digital economy securely, independently and on their own terms. The Microsoft Sovereign Cloud brings together productivity, security and cloud workloads to span both public and private environments. Customers can choose the right control posture for each workload, through a continuum of sovereign options protecting against fragmenting their architecture or increasing operational risk. Trust is built on confidence: confidence that data stays protected, controls are enforceable and operations can continue under real-world conditions. To support these confidential environments, Microsoft offers full stack capabilities that support customers across connected, intermittently connected and fully disconnected modes. Today’s expansion of capabilities includes three major updates: Azure Local disconnected operations (now available) – Organizations can now run mission-critical infrastructure with Azure governance and policy control, with no cloud connectivity, optimizing continuity for sovereign, classified or isolated environments. Microsoft 365 Local disconnected (now available) – Core productivity workloads, Exchange Server, SharePoint Server and Skype for Business Server can run fully inside the customer’s sovereign operational boundary on Azure Local, keeping teams productive even when disconnected from the cloud. Foundry Local adds modern infrastructure capabilities and support for large AI models – Organizations can now bring large AI models into fully disconnected, sovereign environments with Foundry Local. Using modern infrastructure from partners like NVIDIA, customers with sovereign needs will now be able to run multimodal models locally on their own hardware, inside strict sovereign boundaries enabling powerful, local AI inferencing in fully disconnected environments. Run connected or fully disconnected. Sovereign Private Cloud unifies Azure Local, Microsoft 365 Local and Foundry Local, bringing modern infrastructure, productivity and support for large AI models to any operational boundary. This delivers a truly localized full stack experience built on Azure Local infrastructure and Microsoft 365 Local workloads, designed to stay resilient across any connectivity condition, with large models being part of Foundry Local extending the stack to run advanced multimodal models locally, securely, even when fully disconnected. Customers can now help maintain uninterrupted operations, keep mission critical workloads protected and apply consistent governance and policy enforcement, while keeping data, identities and operations within their sovereign boundaries. Azure Local runs critical infrastructure locally, even when disconnected For workloads with specialized requirements, Azure Local provides the on-premises foundation with consistent Azure governance and policy controls. With Azure Local disconnected operations, management, policy and workload execution stay within the customer-operated environments, so services continue running securely even when environments must be isolated or connectivity is not available. Using familiar Azure experiences and consistent policies, organizations can deploy and govern workloads locally without depending on continuous connection to public cloud services. Azure Local is designed to scale with mission-critical needs from smaller deployments to larger footprints that support data-intensive and AI-driven workloads. Customers can start fast, expand over time and maintain a unified operational model, all within their sovereign boundary. Operating in disconnected environments surfaces constraints that go beyond traditional cloud assumptions: External dependencies may be unacceptable, connectivity may be intentionally restricted and operational continuity is a business imperative. “The availability of Azure Local disconnected operations represents a breakthrough for organizations that need control over their data without sacrificing the power of the Microsoft Cloud. For Luxembourg, where digital sovereignty is not just a principle but a strategic necessity, this model offers the resilience, autonomy and trust our market expects. By combining Microsoft’s technological leadership with Proximus NXT’s sovereign cloud expertise, we are enabling our customers to innovate confidently — even in fully disconnected mode,” said Gerard Hoffmann, CEO Proximus Luxembourg. Microsoft 365 Local keeps productivity and collaboration available in fully disconnected environments As sovereign environments move into disconnected environments, keeping people productive becomes just as critical as keeping infrastructure online. Building on more than a decade of delivering and supporting these services, Microsoft 365 Local disconnected brings that continuity to the productivity layer, delivering Microsoft’s core server workloads — Exchange Server, SharePoint Server and Skype for Business Server supported through at least 2035 — directly into the customer’s sovereign private cloud. With Microsoft 365 Local, teams can communicate, share information and collaborate securely within the same controlled boundary as their infrastructure and AI workloads. Everything runs locally, under customer-owned policies, with full control of data resiliency, access and compliance. By operating with Azure-consistent management and governance, customers get the productivity experience they rely on, designed to stay resilient and secure even when offline. Bringing large models and modern infrastructure to Foundry Local With the availability of larger models and modern infrastructure as part of the Foundry Local portfolio, Microsoft is enabling customers with highly secure environments the ability to run multimodal, large models directly inside their sovereign private cloud environments. This brings the richness of Microsoft’s enterprise AI capabilities to on-premises systems, complete with local inferencing and APIs that operate completely within customer-controlled data boundaries. Expanding beyond small models, the integration of Foundry Local with Azure Local is specifically designed to support large-scale models utilizing the latest GPUs from partners such as NVIDIA. Microsoft will provide comprehensive support for deployments, updates and operational health. Even as inferencing demands increase over time, customers retain complete control over their data and hardware. Choice and control without added complexity Customers facing strict sovereignty and regulatory requirements are clear that a fully disconnected sovereign private cloud is a key business need. Microsoft Sovereign Private Cloud is designed to meet these needs head-on, enabling secure, compliant operations even in environments with no external connectivity. At the same time, we recognize that disconnected environments are not one-size-fits-all; some customers operate across connected, hybrid and disconnected modes based on mission, risk and regulation. Our approach helps customers to meet strict sovereign requirements in fully disconnected scenarios without compromising simplicity, while retaining flexibility where connectivity is possible. Together, Azure Local disconnected operations, Microsoft 365 Local and Foundry Local help organizations choose where workloads run and how environments are managed, while standardizing governance and operational practices across connected and disconnected deployments. Get started Azure Local disconnected operations and Microsoft 365 Local disconnected are now available worldwide, and large models on Foundry Local are available to qualified customers. Explore the Microsoft Sovereign Cloud Learn more about Azure Local disconnected operations Douglas Phillips leads global engineering efforts for Microsoft’s specialized, sovereign, and private clouds. He is responsible for Microsoft’s global strategy, products and operations that bring Microsoft’s industry-leading solutions, including Azure, our adaptive cloud portfolio and Microsoft 365 collaboration suite, to customers with additional sovereignty, security, edge and compliance requirements. The post Microsoft Sovereign Cloud adds governance, productivity and support for large AI models securely running even when completely disconnected appeared first on The Official Microsoft Blog. As digital sovereignty becomes a strategic requirement, organizations are rethinking how they deploy critical infrastructure and AI capabilities under tighter regulatory expectations and higher risk conditions. Microsoft’s approach to sovereignty is grounded in enabling enterprises, public sectors and regulated industries to participate in the digital economy securely, independently and on their own terms. The Microsoft Sovereign Cloud brings together productivity, security and cloud workloads to span both… The post Microsoft Sovereign Cloud adds governance, productivity and support for large AI models securely running even when completely disconnected appeared first on The Official Microsoft Blog. Featured, The Official Microsoft Blog, Azure, Foundry, Microsoft 365, Microsoft Sovereign Cloud, Sovereign Private Cloud The Official Microsoft Blog